Les aberrations optiques constituent la limite ultime de performance des télescopes, qui les empêche d'atteindre leur limite théorique de diffraction. Une fois ces aberrations estimées, on peut les compenser en utilisant des miroirs déformables commandés en boucle fermée.
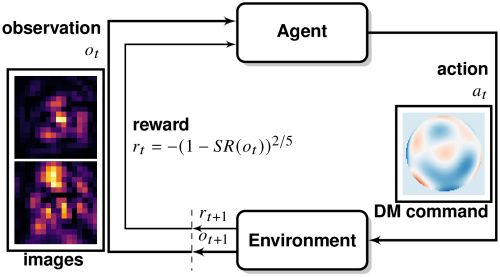
La mesure du front d'onde directement à partir des images obtenues par le capteur scientifique au foyer de l’instrument permet d'estimer les aberrations sur l'ensemble du chemin optique. Cependant, les méthodes actuelles de mesure du front d'onde au foyer reposent sur des modèles physiques dont les inexactitudes peuvent limiter la performance globale de la correction.
Dans un article paru récemment, nous avons développé une méthode entièrement fondée sur les données, sans modèle, en utilisant l'apprentissage par renforcement pour effectuer automatiquement l'estimation et la correction des aberrations. Le entrées de l’algorithme sont des images focalisées et légèrement défocalisée acquises autour du plan focal (dans l’esprit de la méthode dite de la diversité de phase). Nous formulons le problème de correction dans le cadre de l'apprentissage par renforcement et entraînons un agent sur des données simulées. Nous montrons que la méthode est capable d'apprendre de manière fiable une stratégie de contrôle efficace pour diverses conditions réalistes. Nous démontrons également la robustesse de la méthode face à un large éventail de niveaux de bruit.
L'article est disponible ici : https://doi.org/10.1364/OE.529415