MASSIPH (pour Maitriser l'Apprentissage Statistique par la SImulation et la PHysique) est un projet de recherche transverse à l'ONERA, réunissant de nombreux départements afin de mettre en regard des techniques d'apprentissage et l'expertise de l'ONERA en science physique.
La motivation de ce projet est que l'apprentissage (et plus globalement l'IA) devient un outils pour de nombreux domaines scientifiques qui en contre-parties peuvent être des cadres mieux poser pour étudier ces nouvelles techniques.
Organisation
Le projet MASSIPH repose en particulier sur 3 axes
IA explicable et mécanique des fluides :
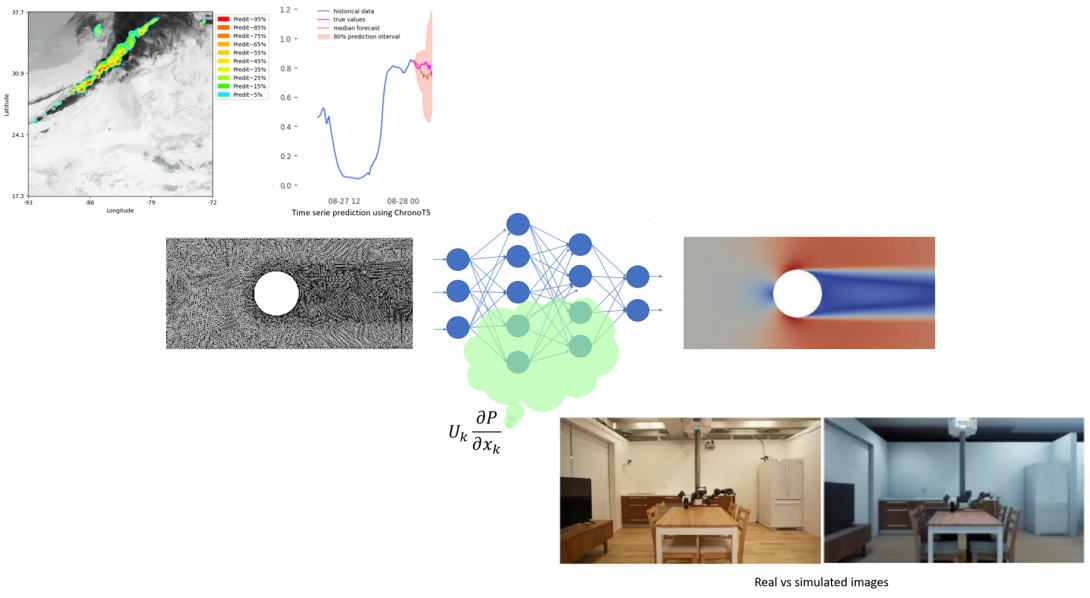
Les méthodes d'apprentissage sont aujourd'hui relativement mal comprises, de nombreuses recherches tentent de développer de l'IA "explicable". Cependant, il n'est pas clair de savoir comment on pourrait expliquer pourquoi une image de chat est une image de chat. Inversement, les données de mécanique des fluides sont contraintes par des lois maitrisées à l'intérieur de l'ONERA. Elles paraissent ainsi un cadre mieux poser pour essayer de comprendre le comportement des réseaux de neurones. Dans le même temps, de nombreux modèles réduits ont été développé pour approximer le champs moyen autour d'une aile d'avion. Ces modèles peuvent prendre plus ou moins de liberté vis à vis de certitudes physiques et la possibilité de disposer de modèles réduits capables d'expliciter les compromis entre l'erreur résiduelle et le relâchement d'une contrainte physique serait intéressant pour la mécanique des fluides.
Calibration et dynamique atmosphérique
L'ONERA étudie depuis de nombreuses années la dynamique atmosphérique pour des applications diverses (prédiction de la qualité du lien sol-sat, prévision des risques météo pour l'aviation, ...). L'utilisation de méthodes d'apprentissage pour améliorer la qualité des modèles existants est une évidence, cependant la nature chaotique de la dynamique atmosphérique nécessite des approches par apprentissage adaptées à la gestion d'incertitude. On peut par exemple penser à la problématique de la calibration d'un modèle de sorte à ce qu'il produise une réponse probabiliste.
Apprentissage et simulation
La possibilité d'apprendre et/ou évaluer un algorithme d'apprentissage sur des données simulées pourrait dévérouiller le développement de méthodes d'apprentissage dans des domaines où les données sont trop rares. Cependant, les données simulées ne sont jamais totalement représentatives des données réelles. Cela invite à considérer les nombreux travaux de recherche sur la robustesse des modèles par apprentissage à des "petites" modifications des données (par exemple les attaques adversaires) et/ou à des modifications représentatives de l'écart entre images réelles et simulées.
Contact
Adrien Chan Hon Tong (DTIS)
Crédit pour les images
https://towardsdatascience.com/a-laymans-guide-to-deep-neural-networks-ddcea24847fb